- Strength in Numbers: The White House Open Source Security Summit
- VMware Named One of America’s Most JUST Companies for 5th Consecutive Year, Awarded Top Environmental Ranking
- Green Software Foundation publishes code efficiency metric, welcomes VMware
- Time to ditch your cloud strategy for a workload placement strategy?
- VMware Multi-Cloud Briefing: January 2022
- vExpert Cloud Management December 2021 Blog Digest
- Innovating Security, What Happens First? With Karen Worstell, Senior Cybersecurity Strategist at VMware
- Virtually Speaking Podcast: Traditional Licensing VS SaaS
- Moving from a Product to a SaaS Mindset
- Nvidia releases updates to AI enterprise suite: Full integration with VMware Tanzu
- Announcing Availability of vSphere 7 Update 3c
- VMware-AWS partnership focuses on scaling and securing the ‘distributed cloud’
- VMware: A Look Ahead at 2022
- Podcast: VMware CEO Raghu Raghuram with IDC President Crawford Del Prete
- White House hosts open-source software security summit in light of expansive Log4j flaw
- Announcing NSX-T 3.2: Innovations in Multi-Cloud Security, Networking, and Operations
- VMware NSX 3.2 Delivers New, Advanced Security Capabilities
- Better Together: Self-Service and Decision Automation for NSX-T 3.2
- Onboarding at VMware: A Virtually Fulfilling Employee Experience
- Cisco, VMware Ask: Does Remote Work Actually Lower Carbon Emissions?
- Applied Chemicals Intl Group gives staff secure remote access with VMware
- Kubernetes in 5 mins
- What Is Kubernetes? 7 Fast Facts From the Founders
- Kubernetes For The VI Admin
- Introducing KubeAcademy Pro: In-Depth Kubernetes Training, Totally Free
- A superior multi-cloud developer experience on Kubernetes
- VMware brings Tanzu Application Platform into GA to ease Kubernetes adoption
- Jan 12 – VMware Tanzu: A Year in Review
- Jan 27 – Getting Started with VMware Tanzu Application Platform
- Getting Started with VMware Tanzu Community Edition
- What don’t people understand about DevOps (yet)?
- VMware {code}: A Year In Review 2021
- VMware Tanzu Momentum Empowers Superior Developer Experiences, Enables Robust Security Practices
- QA Analytics and Its Countless Possibilities
- What’s New in vRealize Network Insight Cloud and vRealize Network Insight 6.4 for NSX-T 3.2
- Explore the complete list of ports required by different VMware products
- VMware and Fidelity named among Glassdoor’s Best Places to Work 2022
Tag: vSphere

VMware Cloud – Continuing VMware’s Force-for-Good for Cloud Choices
One of VMware’s guiding principles is to be a force for good (VMware 2030 Agenda). VMware’s impact to reducing CO2 emissions for customers worldwide has been well documented (VMware Global Impact Report 2020). But in addition to that, VMware’s force for good has enabled customer choice, by liberating organizations from physical constraints. For many years, that meant a choice in hardware to run or access applications. Now, VMware Cloud means customers have a choice to run any application in any cloud with a consistent experience.
From an IT perspective, applications are the center of the universe. For years, IT operational staff have worked to perfect building, running, and managing compute, network, and storage. But none of that would matter if there weren’t applications to run a business.
If there’s a SaaS offering that meets your business needs like Salesforce.com, Workday, and Coupa, then go for it!
For all other applications, the choice is to use a common off-the-shelf software package or build your own. Regardless, that application has to run somewhere, either in the public cloud or in your private data center cloud. There are many factors leading to that choice.
I’ve worked with a large worldwide bank who’s proven that with VMware they can build, run, and manage their own data centers more cost effectively than current big name public cloud providers.
I’ve worked with another financial services company who sees the need for AWS and Azure public clouds so they can burst capacity on demand because having infrastructure on standby is not economically feasible in their own private cloud. However, they need to maintain private clouds to meet the security and performance requirements of some applications. Thus, they require a hybrid cloud and multi cloud strategy.
As you can see, there’s no single clear answer to where applications should reside. That’s why VMware offers choice. One thing is clear, of the organizations VMware studied this year, 90% of executives are prioritizing migration and modernization of their legacy apps. VMware understands that businesses need a range of modernization strategies and the 5R’s of app modernization; Retain, Rehost, Replatform, Refactor, and Retire is designed to do just that.
Retain – If applications must be Retained in a private cloud, then many companies have proven that with VMware Cloud Foundation and vRealize Suite, they can operate their own cloud to achieve the highest levels of performance, availability and efficiency and do it cost effectively, securely, and operationally simple.
Rehost/Migrate – Some customers are choosing to Rehost or Migrate their applications in a public cloud. The good news is that the same private cloud solution that has powered 85 million workloads for the most demanding businesses is available in over 4000 public clouds like VMware Cloud on AWS, Azure VMware Cloud, and 1000’s of our other cloud partners. Applications can be migrated instantly, without disruption or having to recode them and they can be secured and managed the same way as in their own private cloud. Once there, the native cloud service can be leveraged to add new functionality to existing apps.
Replatform – With vSphere 7, VMware brings native Kubernetes support to vSphere. This allows you to Replatform or repackage existing applications into containers and orchestrate them in Kubernetes. In other words, you can run, observe, and manage containers in the same way you manage VMs.
Refactor/Build – VMware has a long history of supporting open-source applications for millions of developers. With VMware Tanzu, developers can build new digital services for the future by
rewriting and Refactoring existing apps to cloud native architecture, Building new ones, deploying them quickly, and operating them seamlessly.
Retire – If you execute your application modernization strategy well, you’ll be able to Retire legacy applications that have been costly to maintain.
VMware believes the needs of your business and applications should drive your cloud strategy. VMware Cloud supports applications deployed across a range of private and public clouds that are unified with centralized management and operations and centralized governance and security.
VMware’s force for good maintains your choice for your applications.
For more information on today’s VMware Cloud announcements, check out: The Distributed, Multi-Cloud Era Has Arrived
VMware for AI & ML Workloads
28 years ago I spent a year preparing a University thesis focused on Neural Networks. Practical usage and the job market wasn’t there back then but lots has changed and Artificial Intelligence and Machine Learning (AI/ML) is everywhere. VMware has been focused on AI/ML for awhile by incorporating it into its products and making it easier for customers to run those types of workloads on top of vSphere. Recently I started looking deeper into this and uncovered some great resources that I thought I would share.
This is a good blog summarizing VMware’s strategic direction: VMware’s AI/ML direction and Hardware Acceleration with vSphere Bitfusion
AI/ML was popular at VMworld 2020 and you can see a list of the focused sessions here: Your Guide to AI/ML Content at VMworld 2020. To view the recorded session, you can go to the VMworld On-Demand Video Library. If you don’t have an account already, you can create one.
Some of the announcements at VMworld 2020:
- The Power of Two: VMware, NVIDIA Bring AI to the Virtual Data Center
- THE DATA CENTER WILL NEVER BE THE SAME – Modernizing the Data Center and Cloud
- Networks on Steroids: VMware, NVIDIA Power the Data Center with DPUs
- VMware’s Project Monterey with NVIDIA BlueField-2 DPU
- Kit Colbert – Use cases for Project Monterey & SmartNic
To keep up to date check out the VMware ML/AI BLOG: VMware Machine Learning & Artificial Intelligence
2-Node Virtual SAN Software Defined Self Healing
I continue to think one of the hidden gem features of VMware Virtual SAN (VSAN) is its software defined self healing ability. I recently received a request for a description of 2-Node self healing. I wrote about our self healing capabilities for 3-Node, 4-Node and more here. And I wrote about Virtual SAN 6 Rack Awareness Software Defined Self Healing with Failure Domains here. I suggest you check out both before reading the rest of this. I also suggest you check out these two posts on 2-Node VSAN for a description on how they work here and are licensed here.
For VSAN, protection levels can be defined through VMware’s Storage Policy Based Management (SPBM) which is built into vSphere and managed through vCenter. VM objects can be assigned to different policy which dictates the protection level they receive on VSAN. With a 2-Node Virtual SAN there is only one option for protection, which is the default # Failures To Tolerate (#FTT) equal to 1 using RAID1 mirroring. In other words, each VM will write to both hosts, if one fails, the data exists on the other host and is accessible as long as the VSAN Witness VM is available.
Now that we support 2-Node VSAN, the smallest VSAN configuration possible is 2 physical nodes with 1 caching device (SSD, PCIe, or NVMe) and 1 capacity device (HDD, SSD, PCIe, or NVMe) each and one virtual node (VSAN Witness VM) to hold all the witness components. Let’s focus on a single VM with the default # Failures To Tolerate (#FTT) equal to 1. A VM has at least 3 objects (namespace, swap, vmdk). Each object has at least 3 components (data mirror 1, data mirror 2, witness) to satisfy #FTT=1. Lets just focus on the vmdk object and say that the VM sits on host 1 with mirror components of its vmdk data on host 1 and 2 and the witness component on the virtual Witness VM (host 3).
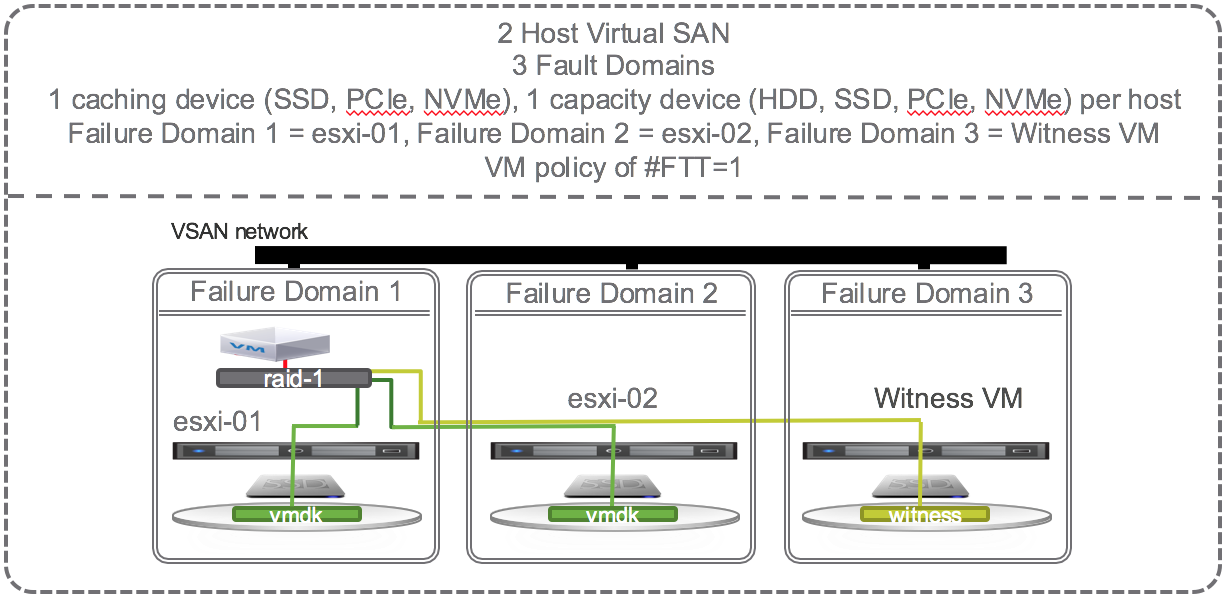
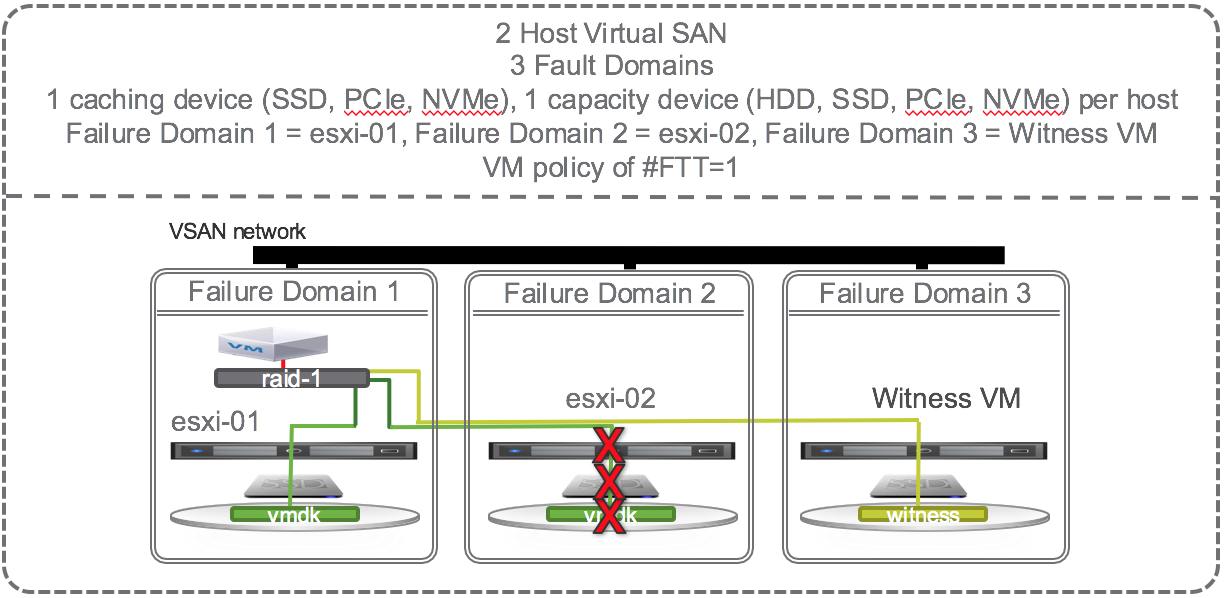
OK, lets start causing some trouble. With the default # Failures To Tolerate equal 1, VM data on VSAN should be available if a single caching device, a single capacity device, or an entire host fails. If a single capacity device fails, lets say the one on esxi-02, no problem, another copy of the vmdk is available on esxi-01 and the witness is available on the Witness VM so all is good. There is no outage, no downtime, VSAN has tolerated 1 failure causing loss of one mirror, and VSAN is doing its job per the defined policy and providing access to the remaining mirror copy of data. Each object has more that 50% of its components available (one mirror and witness are 2 out of 3 i.e. 66% of the components available) so data will continue to be available unless there is a 2nd failure of either the caching device, capacity device, or esxi-01 host. The situation is the same if the caching device on esxi-02 fails or the whole host esxi-02 fails. VM data on VSAN would still be available and accessible. If the VM happened to be running on esxi-02 then HA would fail it over to esxi-01 and data would be available. In this configuration, there is no automatic self healing because there’s no where to self heal to. Host esxi-02 would need to be repaired or replaced in order for self healing to kick in and get back to compliance with both mirrors and witness components available.
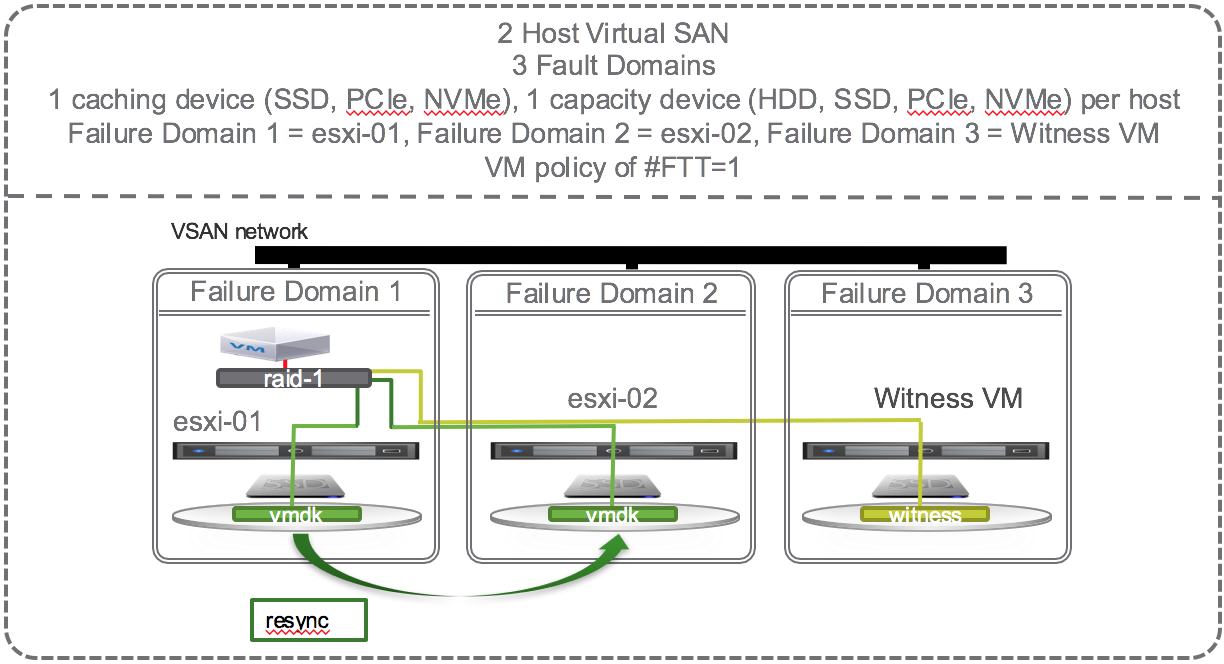
Self healing upon repair
How can we get back to the point where we are able to tolerate another failure? We must repair or replace the failed caching device, capacity device, or failed host. Once repaired or replaced, data will resync, and the VSAN Datastore will be back to compliance where it could then tolerate one failure. With this minimum VSAN configuration, self healing happens only when the failed component is repaired or replaced.
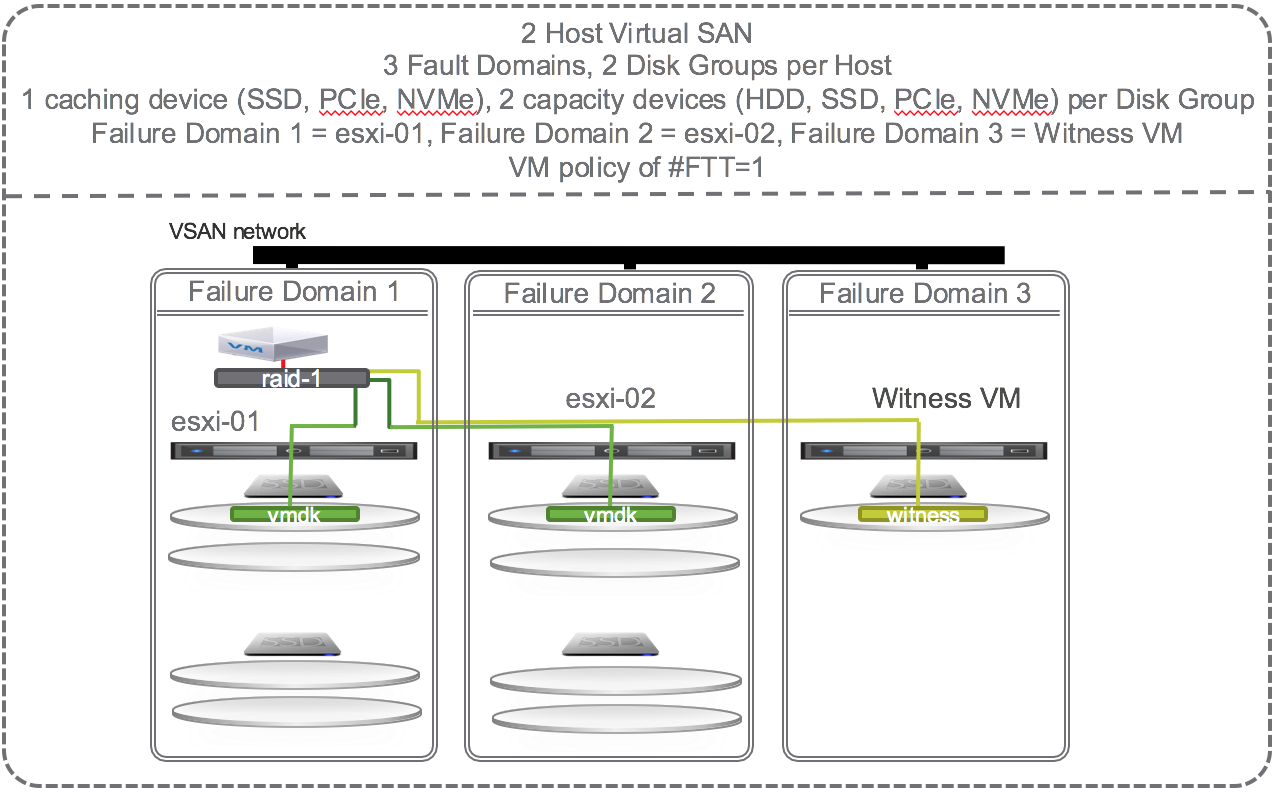
2-Node VSAN Self Healing Within Hosts and Across Cluster
To get self healing within hosts and across the hosts in the cluster you must configure your hosts with more disks. Let’s investigate what happens when there are 2 SSD and 4 HDD per host and 4 hosts in a cluster and the policy is set to # Failures To Tolerate equal 1 using the RAID 1 (mirroring) protection method.
If one of the capacity devices on esxi-02 fails then VSAN could chose to self heal to:
- Other disks in the same disk group
- Other disks on other disk groups on the same host
The green disks in the diagram below are eligible targets for the new instant mirror copy of the vmdk:
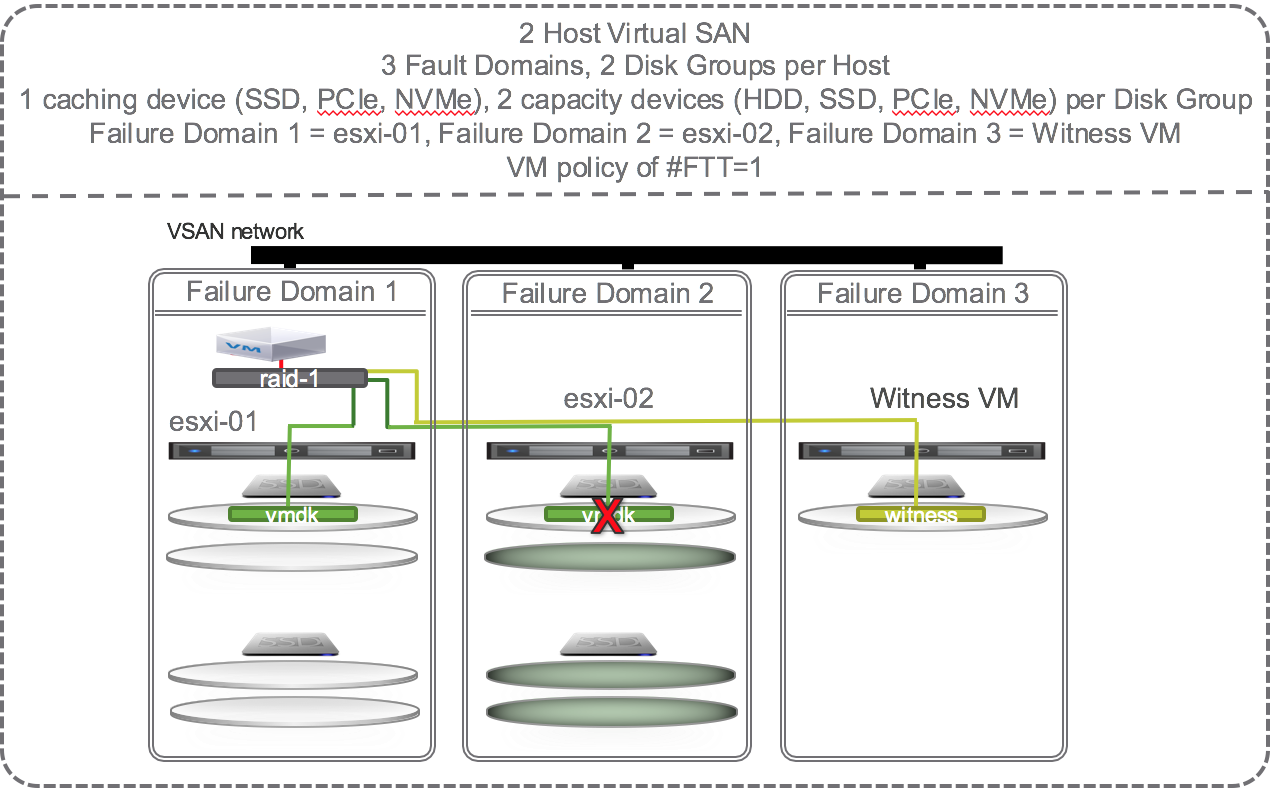
This is not an all encompassing and thorough explanation of all the possible scenarios. There are dependencies on how large the vmdk is, how much spare capacity is available on the disks, and other factors. But, this should give you a good idea of how failures are tolerated and how self healing can kick in to get back to policy compliance.
Self Healing When SSD Fails
If there is a failure of the caching device on esxi-02 that supports the capacity devices that contain the mirror copy of the vmdk then VSAN could chose to self heal to:
- Other disks on other disk groups on the same host
- Other disks on other disk groups on other hosts.
The green disks in the diagram below are eligible targets for the new instant mirror of the vmdk:
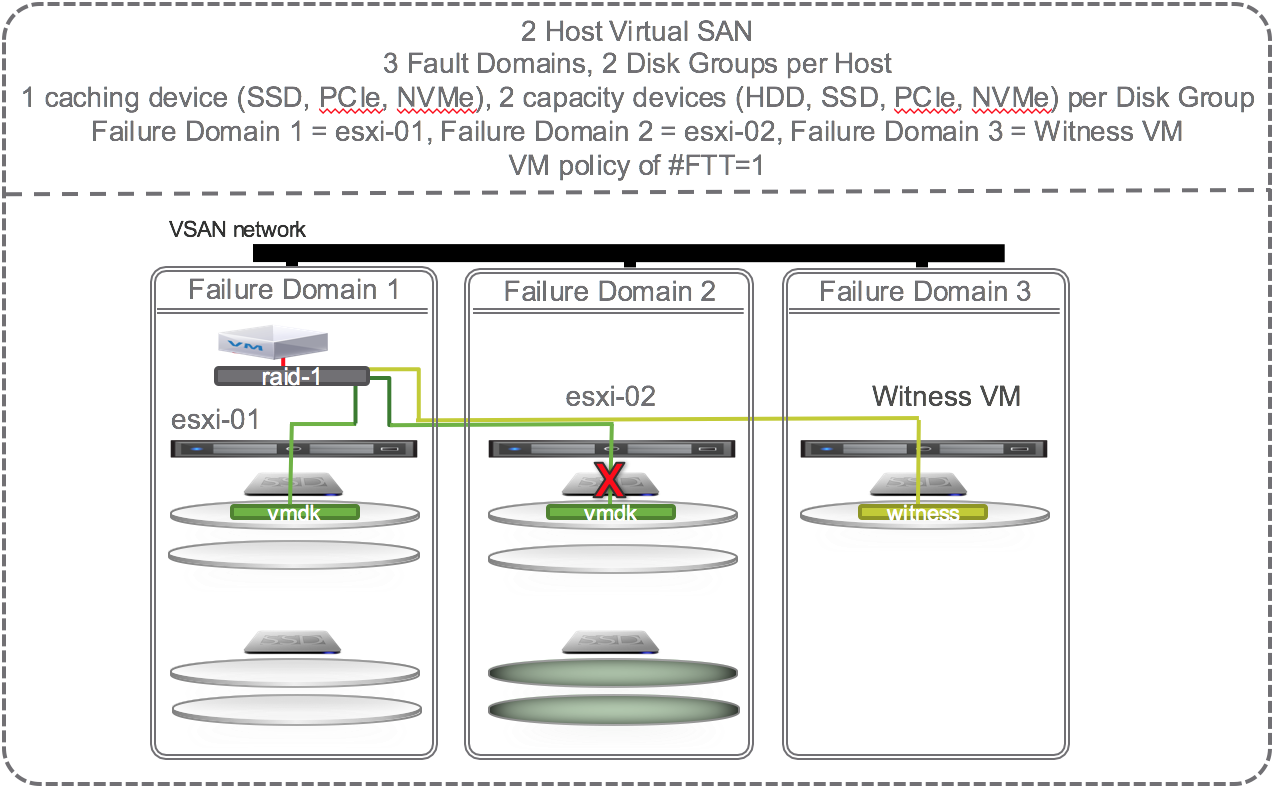
Self Healing When a Host Fails
If there is a failure of a host (e.g. esxi-02) that supports mirror of the vmdk then VSAN cannot self heal until the host is repaired or replaced.

Summary
VMware Virtual SAN leverages all the disks on all the hosts in the VSAN datastore to self heal. Note that I’ve only discussed above the self healing behavior of one VM but other VM’s on other hosts may have data on the same failed disk(s) but their mirror may be on different disks in the cluster and VSAN might choose to self heal to other different disks in the cluster. Thus the self healing workload is a many-to-many operation and thus spread around all the disks in the VSAN datastore.
Self healing is enabled by default, behavior is dependent on the software defined protection policy (#FTT setting), and can occur to disks in the same disk group, to other disk groups on the same host, or to other disks on other hosts. The availability and self healing properties make VSAN a robust storage solution for all data center applications.

VMware Virtual SAN at Storage Field Day 9 (SFD9) – Making Storage Great Again!
On Friday, March 18 I took the opportunity to watch the live Webcast of Storage Field Day 9. If you can carve our some time, I highly recommend this.
Tech Field Day@TechFieldDay
VMware Storage Presents at Storage Field Day 9
The panel of industry experts ask all the tough questions and the great VMware Storage team answers them all.
| Storage Industry Experts | VMware Virtual SAN Experts |
|
|
The ~2 hour presentation was broken up into easily consumable chunks. Here’s a breakdown or the recoded session:
VMware Virtual SAN Overview
In this Introduction, Yanbing Le, Senior Vice President and General Manager, Storage and Availability, discusses VMware’s company success, the state of the storage market, and the success of HCI market leading Virtual SAN in over 3000 customers.
What Is VMware Virtual SAN?
Christos Karamanolis, CTO, Storage and Availability BU, jumps into how Virtual SAN works, answers questions on the use of high endurance and commodity SSD, and how Virtual SAN service levels can be managed through VMware’s common control plane – Storage Policy Based Management.
VMware Virtual SAN 6.2 Features and Enhancements
Christos continues the discussion around VSAN features as they’ve progressed from the 1st generation Virtual SAN released in March 12, 2014 to the 2nd, 3rd, and now 4th generation Virtual SAN that was just released March 16, 2016. The discussion in this section focuses a lot on data protection features like stretched clustering and vSphere Replication. They dove deep into how vSphere Replication can deliver application consistent protection as well as a true 5 minute RPO based on the built in intelligent scheduler sending the data deltas within the 5 minute window, monitoring the SLAs, and alerting if they cannot be met due to network issues.
VMware Virtual SAN Space Efficiency
Deduplication, Compression, Distributed RAID 5 & 6 Erasure Coding are all now available to all flash Virtual SAN configurations. Christos provides the skinny on all these data reduction space efficiency features and how enabling these add very little overhead on the vSphere hosts. Rawlinson chimes on the automated way Virtual SAN can build the cluster of disks and disk groups that deliver the capacity for the shared VSAN datastore. These can certainly be built manually but VMware’s design goal is to make the storage system as automated as possible. The conversation moves to checksum and how Virtual SAN is protecting the integrity of data on disks.
VMware Virtual SAN Performance
OK, this part was incredible! Christos laid down the gauntlet, so to speak. He presented the data behind the testing that shows minimal impact on the hosts when enabling the space efficiency features. Also, he presents performance data for OLTP workloads, VDI, Oracle RACK, etc. All cards on the table here. I can’t begin to summarize, you’ll just need to watch.
VMware Virtual SAN Operational Model
Rawlinson Rivera takes over and does what he does best, throwing all caution to the wind and delivering live demonstrations. He showed the Virtual SAN Health Check and the new Virtual SAN Performance Monitoring and Capacity Management views built into the vSphere Web Client. Towards the end, Howard Marks asked about supporting future Intel NVMe capabilities and Christos’s response was that it’s safe to say VMware is working closely with Intel on ensuring the VMware storage stack can utilize the next generation devices. Virtual SAN already supports the Intel P3700 and P3600 NVMe devices.
This was such a great session I thought I’d promote it and make it easy to check it out. By the way, here’s Rawlinson wearing a special hat!

Queue Depth and the FBWC Controller Cache module on the Cisco 12G SAS Modular Raid Controller for Virtual SAN
If you scan the bill of materials for the various Cisco UCS VSAN ReadyNodes you’ll see a line item for:
Controller Cache: Cisco 12Gbps SAS 1GB FBWC Cache module (Raid 0/1/5/6)
If you’ve followed Virtual SAN for awhile you might wonder, why would the ReadyNodes include controller cache when VMware recommends disabling controller cache when implementing Virtual SAN. Well, it turns out that the presence of the FBWC Cache module allows the queue depth of the Cisco 12G SAS Modular Raid Controller to go from the low 200’s to the advertised 895. The minimum queue depth requirement for Virtual SAN is 256 so including the FBWC Cache module allows the queue depth to increase above that minimum requirement and improve Virtual SAN performance.
Steps to Implement the Correct I/O Controller Driver for the Cisco 12G SAS Modular Raid Controller for Virtual SAN
This is my third post this week, possibly a record for me. All three are centered around ensuring the correct firmware and drivers are installed and running. The content of this post was created by my colleague, David Boone, who works with VMware customers to ensure successful Virtual SAN deployments. When it comes to VSAN, its important to use qualified hardware but equally important to make sure the correct firmware and drivers are installed.
Download the Correct I/O Controller Driver
Navigate to the VMware Compatibility Guide for Virtual SAN, scroll down and select “Build Your Own based on Certified Components”, then find the controller in the database. Here’s the link for the Cisco 12G SAS Modular Raid Controller and the link to download the correct driver for it (as of Nov. 20, 2015): https://my.vmware.com/web/vmware/details?downloadGroup=DT-ESX55-LSI-SCSI-MEGARAID-SAS-660606001VMW&productId=353
Install the Correct Driver
Use your favorite way to install the driver. This might include creating a custom vSphere install image to deploy on multiple hosts, rolling out via vSphere Update Manager (VUM), or manually installing on each host.
How do I determine what ESXi and vCenter builds I am running?
When starting a new VMware project or evaluating new features, it’s always good to start with the latest and greatest software versions. The following describes how to figure out what ESXi, vCenter, and Web Client you are currently running and if they are the latest build number. If not, you should consider upgrading.
Where can I find a list of VMware software versions and build numbers?
VMware vSphere and vCloud suite build numbers table:
How do I determine what ESXi build am I running?
Via the vSphere Web Client
- Log into the VMware vSphere Web Client
- Select a host
- Home à Hosts and Clusters à Datacenter à Cluster à Host
- Select Summary tab
- Find the Configuration box (likely somewhere at the bottom right of screen)
- “ESX/ESXi Version” will tell you the version and build number

Via command line
- Log into the ESXi Shell of a host either by enabling local access and use the local shell on the physical console or enable SSH access and connect via an SSH tool like PuTTY.
- Execute the following command
- vmware –vl
- Results will look something like this:
- VMware ESXi 5.5.0 build-???????
- VMware ESXi 5.5.0 Update 1

How do I determine what vCenter build am I running?
- Log into the VMware vSphere Web Client
- Locate the vCenter Server in the inventory tree
- Home à vCenter à Inventory Lists à vCenter Servers à vCenter Server
- Select the “Summary” tab
- The version is listed in the “Version Information” pane on the right (see screenshot)

How do I determine what vSphere Web Client build am I running
- On the vSphere Web Client
- Help —> About VMware vSphere
- The version is listed in the “Version Information” pane on the right (should look something like)
- vSphere Web Client: Version 5.5.0 Build ???????

Best practice for VMware LUN size
I was asked this question today. Its one of my favorite questions to answer but I’ve never wrote it down. Today I did so here it is. Let me know if you agree or if you have other thoughts.
For a long time VMware’s max LUN size was 2TB. This restriction was not a big issue to many but some wanted larger LUN sizes because of an application requirement. In these cases it was typically one or only a few VM’s accessing the large datastore/LUN. vSphere 5 took the LUN size limit from 2 TB to 64TB. Quite a dramatic improvement and hopefully big enough to satisfy those applications.
For general purpose VMs, prior to vSphere 4.1, the best practice was to keep LUN sizes smaller than 2TB (i.e. even though ESX supports 2TB LUNs, don’t make them that big). 500GB was often recommended. 1TB was OK too. But it really depended on a few factors. In general, the larger the LUN the more VM’s it can support. The reason for keeping the LUN sizes small in the past was to limit the number of VM’s per datastore/LUN. The implication of putting too many VM’s on a datastore/LUN is that performance would suffer. First reason is that vSphere’s native multipathing only leverages one path at a time per datastore/LUN. So if you have multiple datastores/LUN’s then you can leverage multiple paths at the same time. Or, you could go with EMC’s PowerPath/VE to better load balance the IO workload. Second reason is with block storage for vSphere 4.0 and earlier there was a hardware locking issue. This meant that if a VM was powered on, off, suspended, cloned,… then the entire datastore/LUN was locked until the operation was complete thus freezing out the other VM’s utilizing that same datastore/LUN. This was resolved in vSphere 4.1 with VAAI Hardware Offload Locking assuming the underlying storage array supported the API’s. But before VAAI, keeping the LUN sizes small helped administrators limit the number of VM’s on a single datastore/LUN thus reducing the effects of the locking and pathing issues.
OK, that was the history, now for the future. The general direction for VMware is to go with larger and larger pools of compute, network, and storage. Makes the whole cloud thing simpler. Thus the increase of support from 2TB to 64TB LUN’s. I wouldn’t recommend going out and creating 64TB LUN’s all the time. Because of VAAI the locking issue goes away. The pathing issue is still there with native multipathing but if you go with EMC’s PowerPath/VE then that goes away. So then it comes down to how big the customer wants to make their failure domains. The thinking is that the smaller the LUN the less VM’s placed on it thus the less impact if a datastore/LUN were to go away. Of course we go through great lengths to prevent that with five 9’s arrays and redundant storage networks, etc. So, the guidance I’ve been seeing lately is 2TB datastores/LUNs is a good happy medium of not too big and not too small for general purpose VM’s. If the customer has specific requirements to go bigger then that’s fine, it’s supported.
So, in the end, it depends!!!
Oh, and the storage array behavior does have an impact on the decision. In the case of an EMC VNX, assuming a FAST VP pool then the blocks will be distributed across various tiers of drives. If more drives are added to the pool then the VNX will rebalance the blocks to take advantage of all the drives. So whether it’s a 500GB LUN or 50TB LUN, the VNX will balance the overall performance of the pool. Lots of good info here about the latest Inyo release for VNX:
http://virtualgeek.typepad.com/virtual_geek/2012/05/vnx-inyo-is-going-to-blow-some-minds.html
VMware vSphere 5 VAAI support for EMC CX4
In vSphere 4 the VAAI test harness only included functionality. So if a storage array supported the VAAI primitives and passed VMware’s functionality test then VAAI was listed as a feature of the supported array in the Storage/SAN Compatibility Guide. vSphere 5 added a VAAI performance test. This is due to some of the issues it discovered when it released their Thin Provision Reclaim VAAI feature in vSphere 5.
EMC’s CX4 did not pass VMware’s performance test harness for XCOPY/Block Zero. Atomic Test and Set (ATS) Hardware Offloading did pass the performance testing but since the XCOPY/Block Zero didn’t pass then VMware considers all VAAI as unsupported on the CX4.
Chad Sakac (Virtual Geek) lays it all out at the end of the PPT and recording in the post VNX engineering update, and CX4/VAAI vSphere scoop. In that he proposes the following EMC support model:
- Running with VAAI block acceleration on a CX4 with ESX5 is considered an unsupported configuration by VMware.
- EMC will support the use of VAAI block under ESX5 with CX4 arrays.
- If customers running this configuration have an issue, EMC recommends they turn off the VAAI features. If the condition persists, VMware will accept the case. If the problem is no longer occurring, contact EMC for support.
vSphere 4 did not have a performance test harness. So if they were happily running vSphere 4 with VAAI enabled then they can upgrade to vSphere 5, leave VAAI enabled, and likely enjoy the same experience they have now for their CX4 on vSphere 4.
