I think one of the hidden gem features of VMware Virtual SAN (VSAN) is it’s software defined self healing ability. On the surface this concept is simple. The entire pool of disks in VSAN are used as hot spares. In the event of a failure, data from the failed disks or hosts are found on other disks in the cluster and replicas (mirrors) are rebuilt onto other disks in the cluster to get back to having redundant copies for protection. For VSAN, the protection level is defined through VMware’s Storage Policy Based Management (SPBM) which is built into vSphere and managed through vCenter. OK, lets get into the details.
Lets start with the smallest VSAN configuration possible that provides redundancy, a 3 host vSphere cluster with VSAN enabled and 1 SSD and 1 HDD per host. And, lets start with a single VM with the default # Failures To Tolerate (#FTT) equal to 1. A VM has at least 3 objects (namespace, swap, vmdk). Each object has 3 components (data 1, data 2, witness) to satisfy #FTT=1. Lets just focus on the vmdk object and say that the VM sits on host 1 with copies of its vmdk data on host 1 and 2 and the witness on host 3.
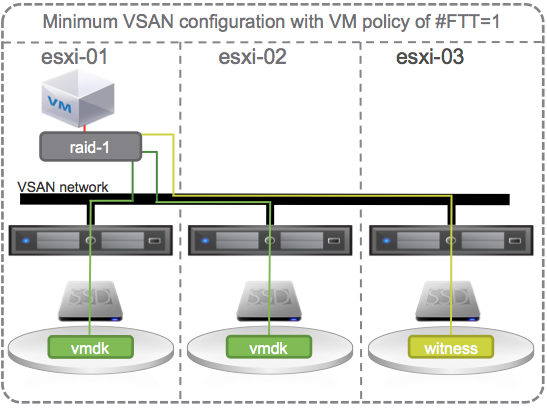
OK, lets start causing some trouble. With the default # Failures To Tolerate equal 1, VM data on VSAN should be available if a single SSD, a single HDD, or an entire host fails.
If a single HDD fails, lets say the one on esxi-02, no problem, another copy of the vmdk is available on esxi-01 and the witness is available somewhere else (on esxi-03) so all is good. There is no outage, no downtime, VSAN has tolerated 1 failure causing loss of one mirror, and VSAN is doing its job per the defined policy and providing access to the remaining mirror copy of data. Each object has more that 50% of its components available so data will continue to be available unless there is a 2nd failure. Actually, the SSD on host 2 could fail or host 2 itself could fail and VM data on VSAN would still be available.
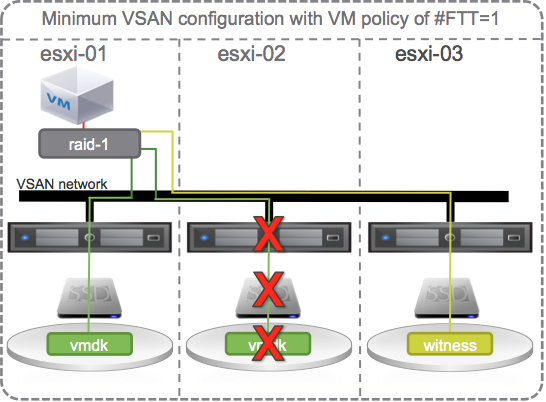
Self healing upon repair
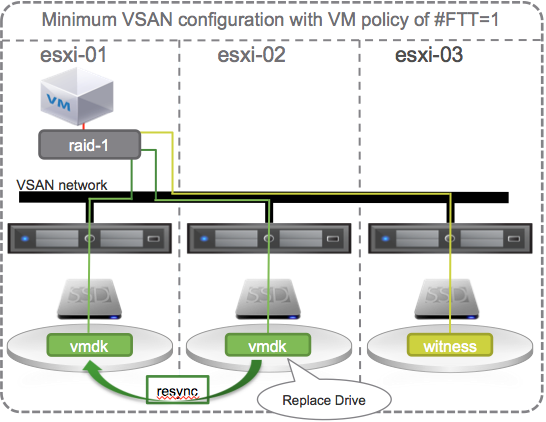
Back to the original failure, the single HDD. If it fails, data is still available, but the policy is now out of compliance and the VSAN Datastore is no longer able to tolerate another failure on other hosts or the data will become unavailable. How can we get back to the point where we are able to tolerate another failure? One way is to replace the failed HDD. Once replaced, data will sync to it, and the VSAN Datastore will be back to compliance where it could then tolerate one failure. With this minimum VSAN configuration, self healing happens only when the failed component is repaired or replaced.
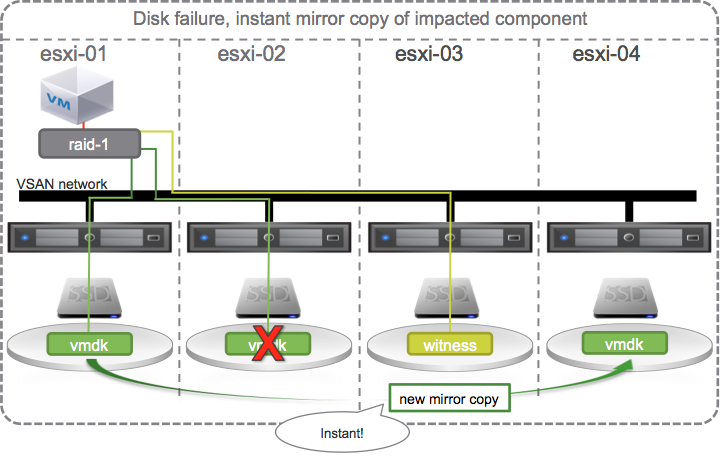
Self Healing with 4 hosts
If we happened to build our cluster with 4 hosts.
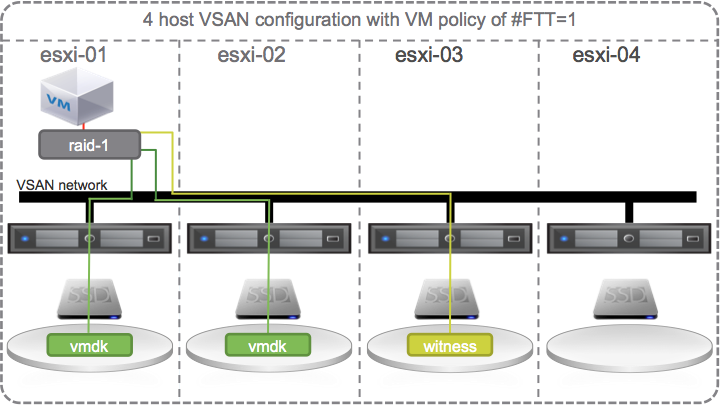
Then rather than waiting to replace the failed disk on esxi-02, VSAN could use the hard disk drive on esxi-04 to instantly recreate the new mirror copy.
Duncan Epping created a good write up on the merits of 4 host clusters here:
4 is the minimum number of hosts for VSAN if you ask me
http://www.yellow-bricks.com/2013/10/24/4-minimum-number-hosts-vsan-ask/
At some point in time when the failed HDD is repaired or replaced it will simply join back into the pool of capacity.
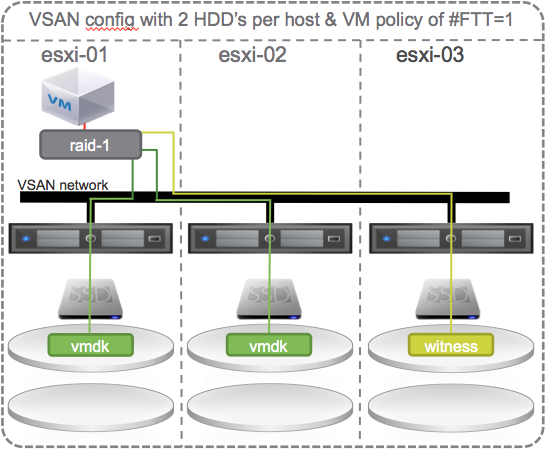
Instant Self Healing with 3 hosts
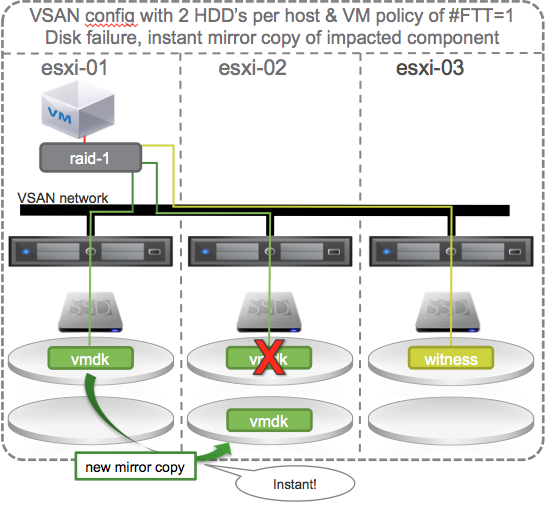
Keep in mind that you don’t need 4 hosts to get instant self healing. If you build your 3 node cluster with more than one hard disk drive per host…
…then self healing occurs within the host. If a HDD fails the other HDD on the same host can be used to self heal and rebuild the mirror.
Self Healing Within Hosts and Across Cluster
To get self healing within hosts and across the cluster with policy set to # Failures To Tolerate equal 1 you could configure your hosts with at least 2 SSD and 4 HDD per host and 4 hosts in a cluster.

If the same HDD on esxi-02 fails then VSAN could chose to self heal to:
- Other disks in the same disk group
- Other disks on other disk groups on the same host
- Other disks on other disk groups on other hosts.
All the green disks in the diagram below are eligible targets for the new instant mirror copy of the vmdk:
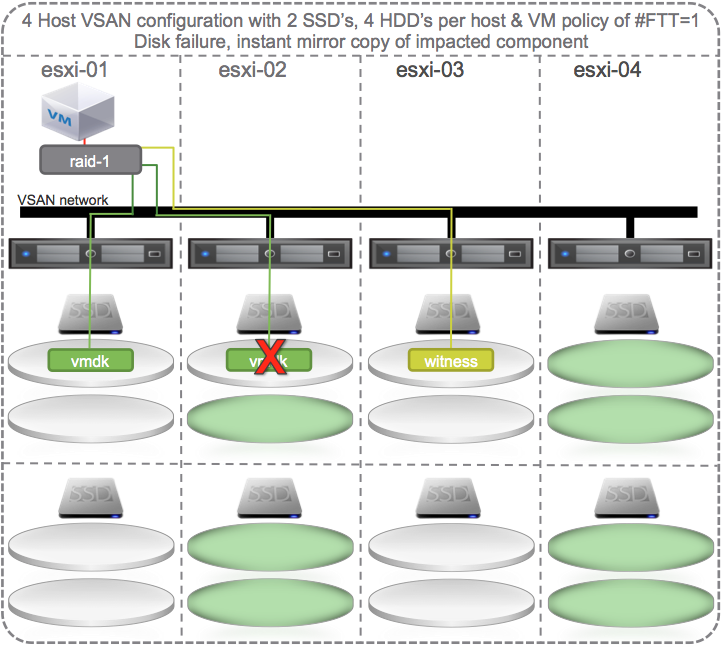
This is not an all encompassing and thorough explanation of all the possible scenarios. There are dependencies on how large the vmdk is, how much spare capacity is available on the disks, and other factors. But, this should give you a good idea of how failures are tolerated and how self healing can kick in to get back to policy compliance.
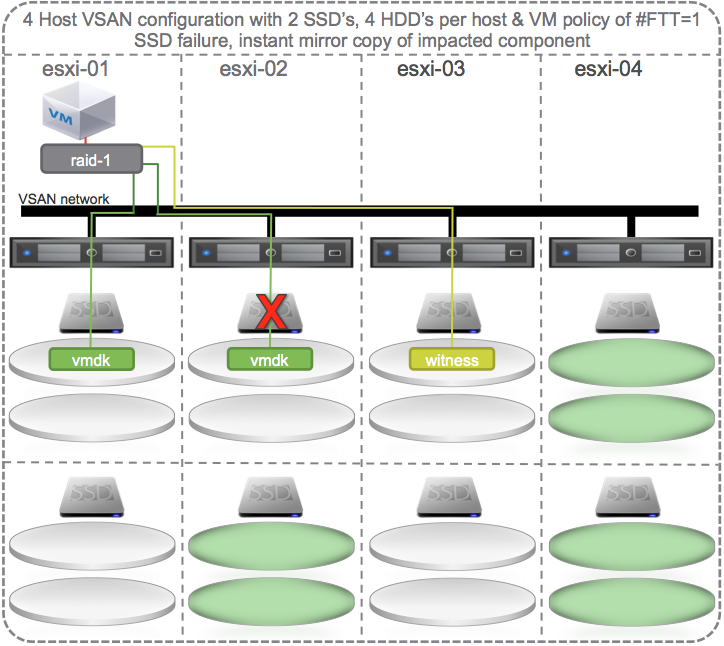
Self Healing When SSD Fails
If there is a failure of the SDD on esxi-02 that supports the HDD’s that contain the mirror copy of the vmdk then VSAN could chose to self heal to:
- Other disks on other disk groups on the same host
- Other disks on other disk groups on other hosts.
All the green disks in the diagram below are eligible targets for the new instant mirror of the vmdk:
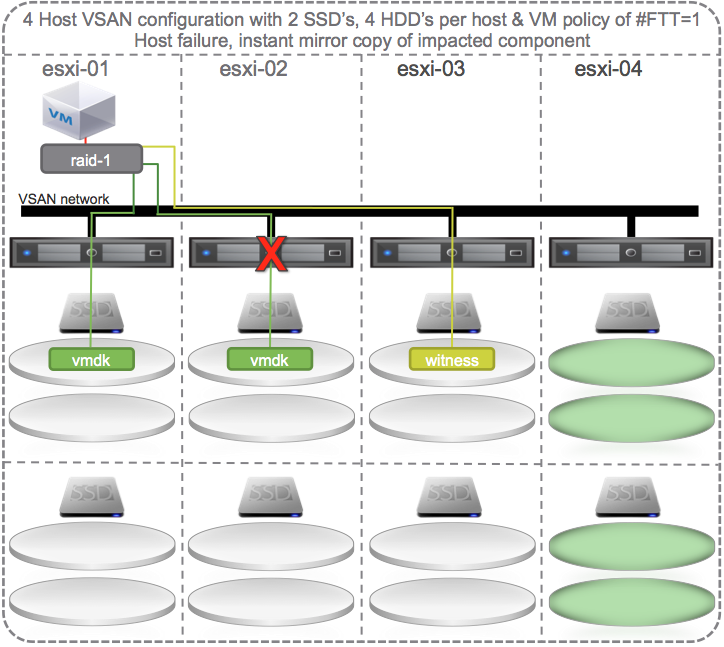
Self Healing When a Host Fails
If there is a failure of a host (e.g. esxi-02) that supports mirror of the vmdk then VSAN could chose to self heal to:
- Other disks on other disk groups on other hosts.
All the green disks in the diagram below are eligible targets for the new instant mirror of the vmdk:
Summary
VMware Virtual SAN leverages all the disks on all the hosts in the VSAN datastore to self heal. Note that I’ve only discussed above the self healing behavior of one VM but other VM’s on other hosts may have data on the same failed disk(s) but might choose to self heal to different disks in the cluster. Thus the self healing workload is spread around all the disks in the VSAN datastore.
Self healing is enabled by default, behavior is dependent on the software defined protection policy (#FTT setting), and can occur to disks in the same disk group, to other disk groups on the same host, or to other disks on other hosts. The availability and self healing properties make VSAN a robust storage solution for many data center applications.

may I raid 10 settings for each disk
If the controller does not support passthrough then each disk must be in its own RAID 0 disk group. So no, you may not put disks in RAID 10.
Thank you, very nice visualization. I have four servers, two in each rack and want to create a four node cluster. I would like to ensure that mirrored FTT=1 data object copies reside by default in the opposing rack… Ideally like a host affinity setting or something. My other option is create two 2 node + witness clusters across the racks but that’s kind of a pain. (I can’t afford more hardware and/or vsan enterprise which I need for the fault domain/rack awareness features). Thanks!
I’m sorry I’m slow on the response. A vSAN object by default requires 3 components to establish quorum and is able to lose one of them to maintain access to the data. Therefor your design wouldn’t work because the witness would need to be in one of the 2 remaining hosts. So, if the rack with one of the copies and the witness were to lose power, that would only leave 1 copy left and vSAN would deny access to that data. What you really want is 3 racks with hosts and use the rack awareness feature of vSAN to basically behave like an automated host affinity. vSAN would make sure one data component is in one rack, another data component is in another rack, and the witness is a third rack. Hope that makes sense. Se here for more details. https://storagehub.vmware.com/t/vmware-vsan/vsan-availability-technologies/rack-awareness-4/