
I continue to think one of the hidden gem features of VMware Virtual SAN (VSAN) is it’s software defined self healing ability. I wrote about it a few months back here in: Virtual SAN Software Defined Self Healing
Since Virtual SAN is such a different way to do storage, it allows for some interesting configuration combinations. With vSphere 6 (built into vSphere 6), VMware will be introducing a new add-on feature for Virtual SAN called “Rack Awareness” accomplished by creating multiple “Failure Domains” and placing hosts in the same rack into the same Failure Domain. This “Rack Awareness” feature exploits the # Failures To Tolerate policy of Virtual SAN.
The rest of this post will look a lot like the previous post I did on self healing but will translate it for the Rack Awareness feature.
Minimum Rack Awareness Configuration
Lets start with the smallest VSAN “Rack Awareness” configuration possible that provides redundancy: a 3 rack, 6 host (2 per rack) vSphere cluster with VSAN enabled and 1 SSD and 1 HDD per host. In VSAN, an SSD constitutes a disk group so the 1 HDD is placed into a Disk Group with the 1 SSD. The SSD performs the write and read caching for the HDD’s in its disk group. The HDD permanently stores the data.
Lets start with a single VM with the default # Failures To Tolerate (#FTT) equal to 1. A VM has at least 3 objects (namespace, swap, vmdk). Each object has 3 components (data 1, data 2, witness) to satisfy #FTT=1. Lets just focus on the vmdk object and say that the VM sits on host 1 with replicas/mirrors/copies (these terms can be used interchangeably) of its vmdk data on host 1 in rack 1 and host 2 in rack 2 and the witness on host 3 in rack 3. The rule in Virtual SAN is that each of these three components of an object (data 1, data 2, witness) must sit on different hosts. With Rack Awareness, they also must be in different hosts in different racks.
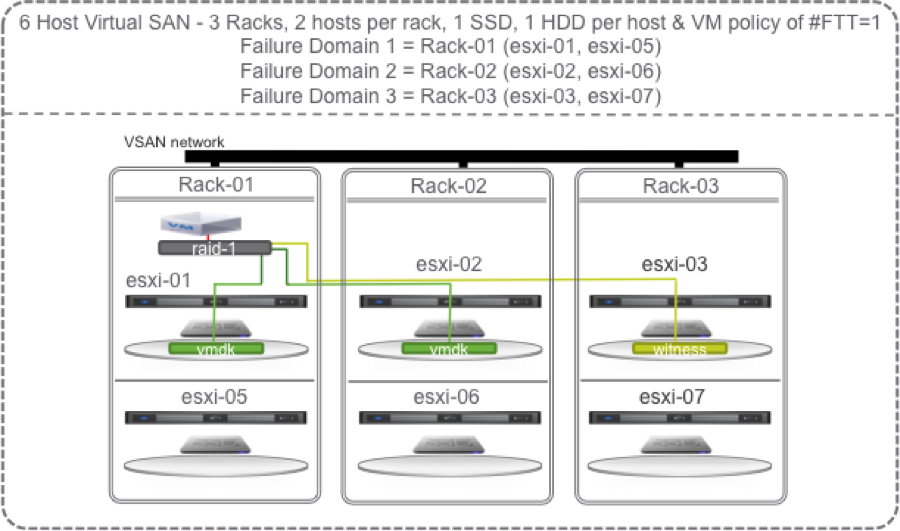
OK, lets start causing some trouble. With the default # Failures To Tolerate equal 1, VM data on VSAN should be available if a single SSD, a single HDD, a single host fails, or an entire rack fails.
If a single HDD fails, lets say the one on esxi-02, no problem, another copy of the vmdk is available on esxi-01 and the witness is available somewhere else (on esxi-03) so all is good. There is no outage, no downtime, VSAN has tolerated 1 failure causing loss of one mirror, and VSAN is doing its job per the defined policy and providing access to the remaining mirror copy of data. Each object has more that 50% of its components available so data will continue to be available unless there is a 2nd failure. Actually, the SSD on host 2 could fail or host 2 itself could fail and VM data on VSAN would still be available. If the HDD or the SSD fail, VSAN will immediately start the self healing process if an eligible disk is available and it has enough spare capacity. If the whole host 2 failed, then VSAN would wait 60 minutes before initiating self healing. This is to allow an administrator to correct the problem rather than immediately starting the self healing process.
The green disk in the diagram below is an eligible target for the new instant mirror of the vmdk:
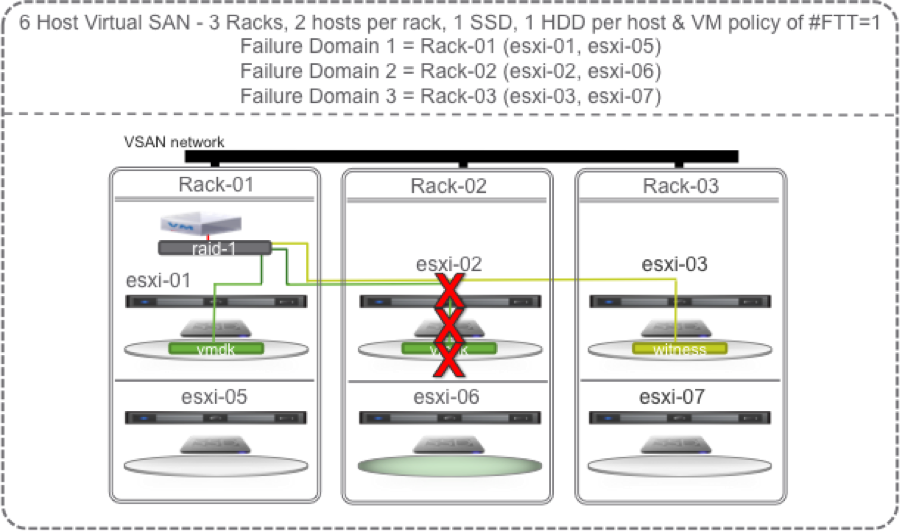
With this minimum Rack Awareness Virtual SAN configuration, self healing can happen to another host in the same rack or when the failed component is repaired or replaced. If there is not enough capacity on host 6 to self heal to then we can replace the failed HDD with a new good one. Once replaced, data will sync to it (self heal), and the VSAN Datastore will be back to compliance where it could then tolerate one failure again.
Now, what if we lose the whole rack 2?
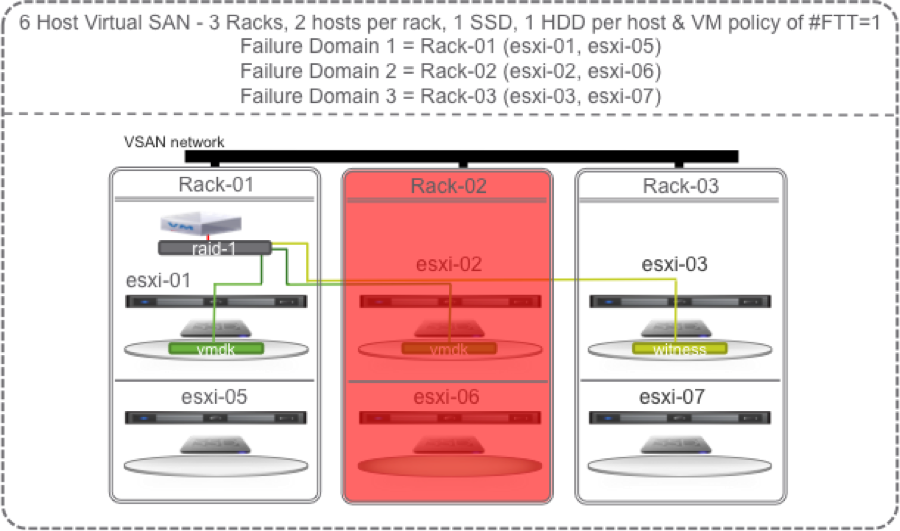
No problem, we still have access to the data on host 1 and the witness on host 3 so the VM can continue operation. But, Virtual SAN cannot self heal until at least 1 host in Rack-02 is restored to operation or replaced.
Self Healing with 4 racks
If we happened to build our cluster with 4 racks:
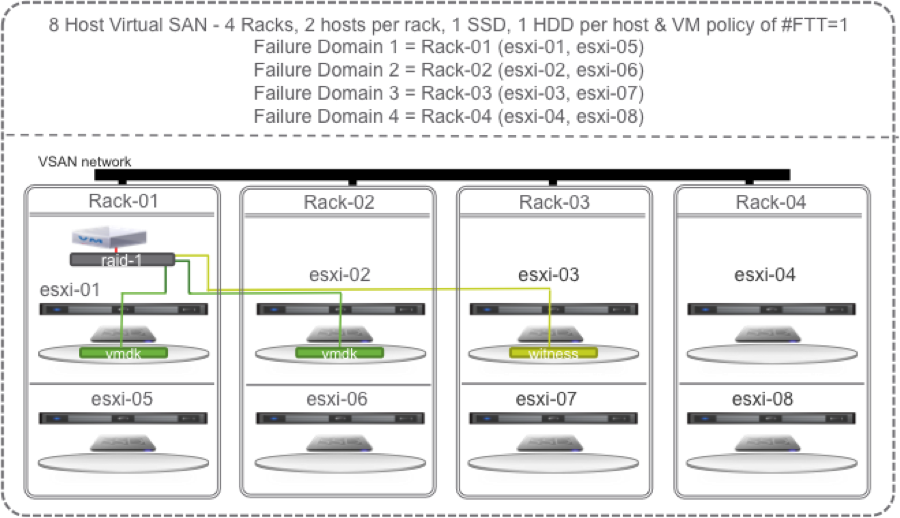
… and we lose the disk on esxi-02, VSAN could use the hard disk drive on esxi-06, esxi-04, or esxi-08 to instantly recreate the new mirror copy.
All the green disks in the diagram below are eligible targets for the new instant mirror of the vmdk:
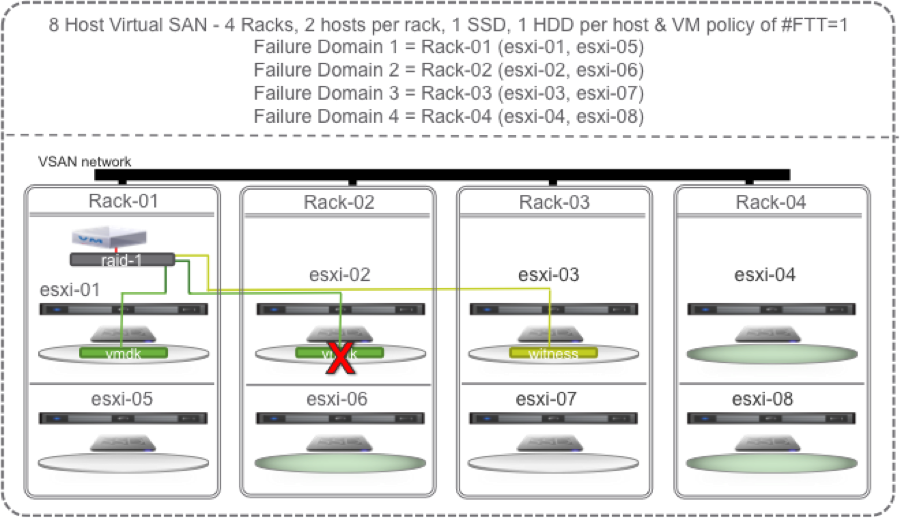
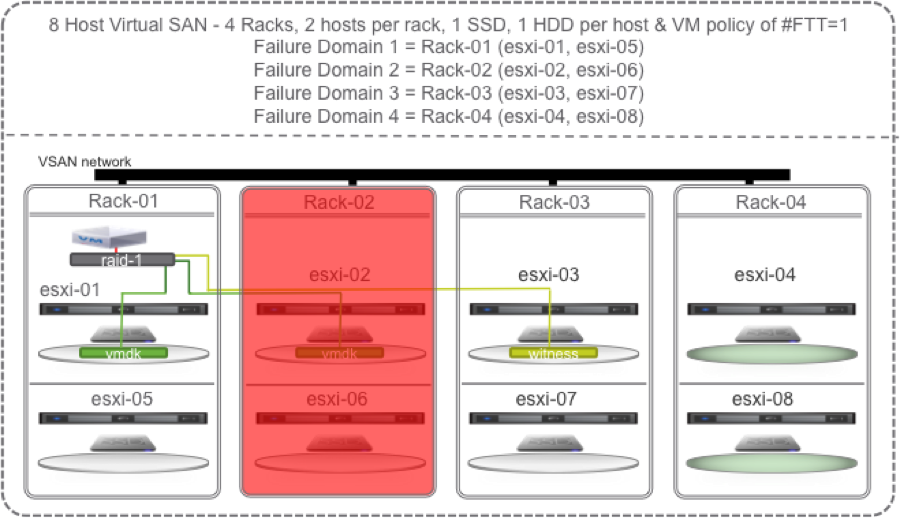
If we lose one of the racks, then rather than waiting to repair or replace the hosts in the failed rack, VSAN can use the hosts in Rack-04 to self heal.
All the green disks in the diagram below are eligible targets for the new instant mirror of the vmdk:
Duncan Epping created a good write up on the merits of 4 host clusters here: 4 is the minimum number of hosts for VSAN if you ask me
Well, the same holds true for dealing with entire rack failures. If a whole rack is lost, it’s nice to have a 4th rack available to handle the instant self healing. It’s important to note that the 4th rack is a “nice to have”. You still get high availability and are able to tolerate failures with 3 Racks. You can even get self healing within a host if there are multiple disk groups in a host, or within the rack if there are multiple hosts in a rack (it wouldn’t make sense not to have multiple hosts in a rack). But if the entire rack fails, the only way to get self healing without repairing the hosts in the failed rack is by having a 4th rack.
Maximizing Self Healing Within Hosts, Racks, and Across the Cluster
To maximize Virtual SAN’s self healing capabilities with policy set to # Failures To Tolerate equal 1 you could configure at least 4 racks, at least 2 hosts per rack, and at least 2 SSD and 4 HDD per host. In the diagrams to follow I happened to go with 3 hosts per rack.

If the HDD on esxi-02 fails then VSAN could chose to self heal to:
- Other disks in the same disk group
- Other disks on other disk groups on the same host
- Other disks on other disk groups on hosts in the same rack
- Other disks on other disk groups on other hosts in a rack that doesn’t already contain one of the components (data 1, data 2, or witness).
All the green disks in the diagram below are eligible targets for the new instant mirror copy of the vmdk:

This is not an all encompassing and thorough explanation of all the possible scenarios. There are dependencies on how large the vmdk is, how much spare capacity is available on the disks, and other factors. But, this should give you a good idea of how failures are tolerated and how self healing can kick in to get back to policy compliance.
If there is a failure of the SDD on esxi-02 that supports the HDD’s that contain the mirror copy of the vmdk then VSAN could chose to self heal to:
- Other disks on other disk groups on the same host
- Other disks on other disk groups on hosts in the same rack
- Other disks on other disk groups on other hosts in a rack that doesn’t already contain one of the components (data 1, data 2, or witness).
All the green disks in the diagram below are eligible targets for the new instant mirror of the vmdk:

If there is a failure of a host (e.g. esxi-02) that supports a mirror of the vmdk then VSAN could chose to self heal to:
- Other disks on other disk groups on hosts in the same rack
- Other disks on other disk groups on other hosts in a rack that doesn’t already contain one of the components (data 1, data 2, or witness).
All the green disks in the diagram below are eligible targets for the new instant mirror of the vmdk:

Finally, if there is a failure of an entire rack (e.g. Rack-02) that supports a mirror of the vmdk then VSAN could chose to self heal to:
- Other disks on other disk groups on other hosts in a rack that doesn’t already contain one of the components (data 1, data 2, or witness).
All the green disks in the diagram below are eligible targets for the new instant mirror of the vmdk:

Summary
Virtual SAN is free to place virtual machine object components (data 1, data 2, and witness) on any three hosts. With Rack Awareness, VSAN is free to place virtual machine object components on any three hosts as long as those hosts aren’t in the same rack. A VM with two vmdk’s might have the data laid out as above on host 1, 2, 3 but the other vmdk might place data 1 on host 3, data 2 on host 5, and the witness on host 12. In other words, Virtual SAN spreads the load of various object components across all the different disks in the cluster while maintaining the defined policy. All hosts and their disks are active and participating in both delivering storage to VM’s but also in being a hot spare when self healing is needed. Thus, there is no need for hot spare disks that are not participating in the VSAN Datastore. And the 4th rack is not there waiting for a failure. The hosts in it are handling ~25% of the overall VM workload just like the other racks and it’s excess capacity can be leveraged when self healing is necessary. When it comes time to self heal, VSAN will choose the best of the eligible disk(s) to do it on based on workload and free capacity.
Self healing is enabled by default, behavior is dependent on the software defined protection policy (#FTT setting), and can occur to disks in the same disk group, to other disk groups on the same host, or to other disks on other hosts. With Rack Awareness enabled, those other hosts can be in the same rack as the hosts with the failed disk or to hosts in a rack that doesn’t already contain one of the other components (data 1, data 2, or witness). The availability and self healing properties make Virtual SAN a robust storage solution for many enterprise data center applications. The new Rack Awareness feature in Virtual SAN 6 is something our customers requested and our awesome VSAN product team delivered it. Stay tuned for more to come.

3 thoughts on “Virtual SAN 6 Rack Awareness – Software Defined Self Healing with Failure Domains”